Context Jamming·Vol. 26 · Dispatch·ACRA Insight LLC
Strategic Briefing · Silicon & Architecture
The Geometry Trade.
The AI industry just stopped scaling and started sculpting: a December 2025 proof that every neural network collapses into the same low-rank geometry has turned chip design into an act of cartography.
For three years the governing metaphor of artificial intelligence was the pile. More data, more parameters, more GPUs, more gigawatts — stack it high enough and capability would emerge from the heap. June 2026 is the month that metaphor died. What replaced it is not bigger. It is more precise. The industry has stopped scaling and started sculpting, and the chisel is geometry.
The evidence arrived as three apparently unrelated headlines that are, on inspection, a single event. On December 6, 2025, Prakhar Kaushik and a team at Johns Hopkins published “The Universal Weight Subspace Hypothesis,” a paper proving empirically that deep neural networks — whatever their architecture, data, or task — collapse into the same low-rank geometric subspace. Later that month, Nvidia paid $20 billion not to buy the inference startup Groq but to license its deterministic chip architecture and absorb its engineering leadership, including TPU pioneer Jonathan Ross. And on June 6, 2026, Clive Chan, OpenAI’s self-described “second hardware hire,” walked across the street to Anthropic to chase a single ratio: perplexity per picojoule.
Read separately, these are a research result, an acqui-hire, and a talent-war skirmish. Read together, they are the financialization of one architectural bet — the wager that the future of AI belongs to whoever can etch the geometry of cognition directly into silicon, and that the capital required to do it can only come from the public markets.
The Proof That Started It
Begin with the physics, because the physics is what makes the rest rational rather than frenzied. For years the field assumed that overparameterized models — networks with billions or trillions of weights — wandered off into distinct, idiosyncratic regions of parameter space, each finding its own private solution. Kaushik’s team tested that assumption at scale, running spectral analysis on more than 1,100 independently trained models: 500 Mistral-7B adapters, 500 vision transformers, 50 LLaMA3-8B models, 200 GPT-2 instances, and a handful of Flan-T5s.
The result was uncomfortable for anyone holding inventory in general-purpose hardware. Five hundred vision transformers trained on completely disjoint datasets — medical scans, satellite imagery, synthetic frames, natural photographs — with random initializations and different hyperparameters, all collapsed into the same low-rank subspace. The architecture, not the data, dictated the geometry. The team showed they could compress all 500 models into a single “Universal ViT” that needed 100 times less memory while holding state-of-the-art performance on out-of-distribution tasks.
If you have followed the argument for architectural determinism, you will recognize the shape of this claim. The thesis that structural priors propagate downstream into the systems they shape turns out to hold at the level of transistors, not just labs. The structure dominates. Everything else is residual.
The Hardware That Follows From It
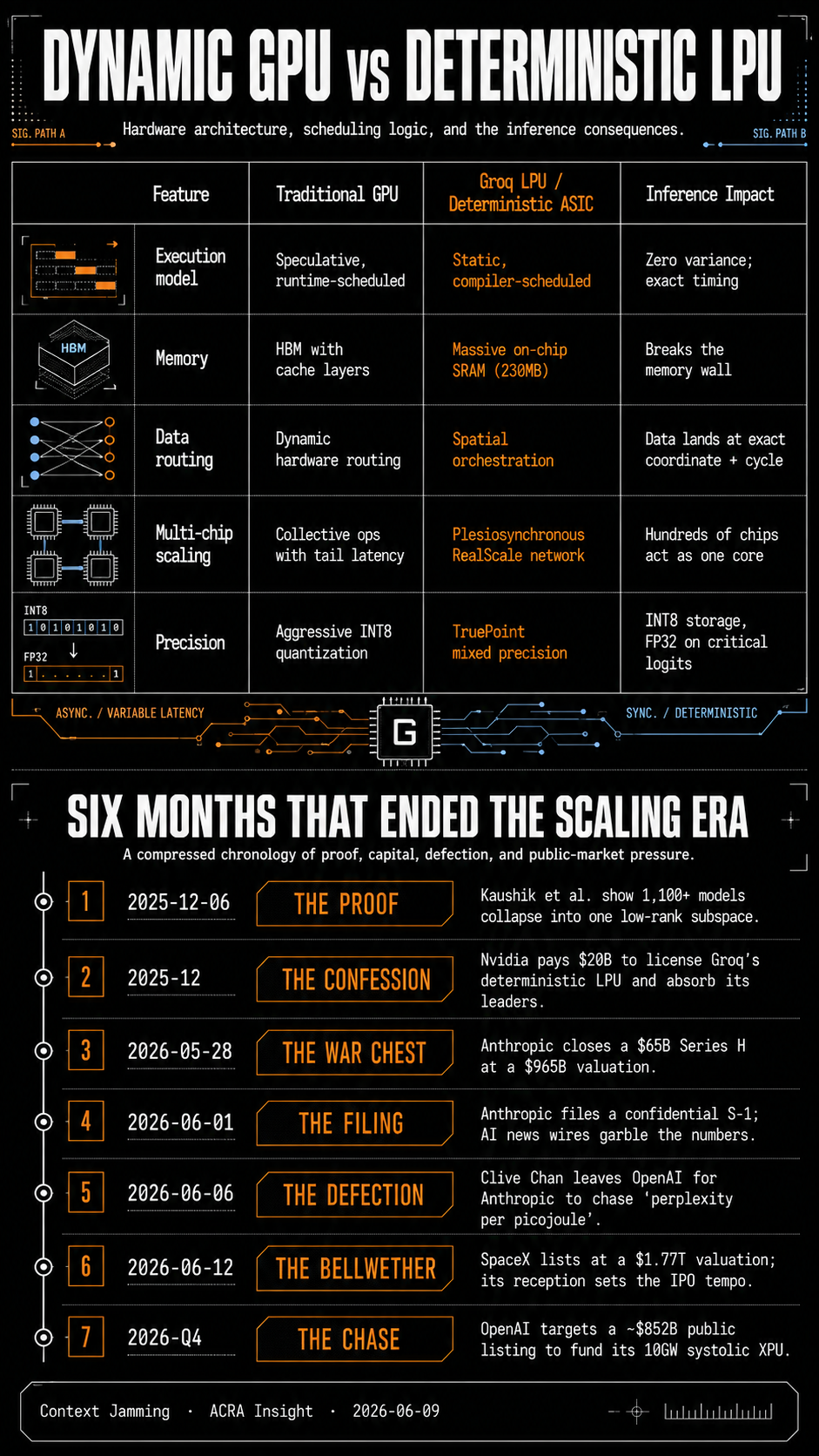
Here is the part the market understood before it could articulate it. If thousands of differently trained networks all live in the same low-dimensional geometry, then running them on dynamic, general-purpose GPUs is a category error. A GPU spends most of its energy not on math but on uncertainty management — cache coherency, reorder buffers, speculative execution — machinery built to handle unpredictable workloads. But inference is not unpredictable. It is the same linear algebra, over and over. Using a GPU for it is like routing a single high-speed train through a city grid of dynamic traffic lights. The infrastructure is the friction.
Groq’s answer, the architecture Nvidia just paid $20 billion to absorb, removes the uncertainty entirely. Its Language Processing Unit pushes all the intelligence into the compiler. Before a model runs, the compiler calculates the exact clock cycle of every operation; if it says a task takes 28.5 milliseconds, it takes 28.5 milliseconds, every time, with zero variance. That determinism lets the chip discard the power-hungry scheduling hardware altogether. Data is mapped spatially across the physical silicon — at a precise cycle, a specific packet arrives at a specific coordinate — and a plesiosynchronous interconnect lets hundreds of chips behave as one core without the tail latency that strangles GPU clusters. Its TruePoint numerics store cheaply in INT8 inside 230MB of on-chip SRAM and compute critically in FP32, breaking the memory wall without breaking accuracy.
Nvidia, the company that sold the pile, just bought the chisel. That is the tell. The dominant incumbent does not pay $20 billion to neutralize a startup it could out-engineer; it pays to admit that brute-force scaling has hit terminal diminishing returns. The Kaushik paper explains why. If the cognitive subspace is universally low-rank, you can etch the physical layout of the transistors to mirror its principal components, throw away the orthogonal noise, and run a frontier model on a fraction of the bandwidth. That is what Chan means by perplexity per picojoule, and it is why his defection matters more than the usual talent churn.
It also exposes a quiet strategic divergence. OpenAI’s in-house XPU program, led by ex-Google engineer Richard Ho and built with Broadcom on TSMC’s 3-nanometer process, is a systolic array — a conventional, brute-throughput design, scaled to a 10-gigawatt commitment. It is excellent at matrix multiplication and indifferent to geometry. Anthropic, with Chan now optimizing for energy per unit of intelligence, appears to be betting on the harder, geometrically tailored path. If that bet lands, scale alone will not save the systolic strategy.
The Capital That Forces the IPO
None of this is cheap. A single gigawatt of this infrastructure costs an estimated $35 to $50 billion, and frontier labs are committing to gigawatts by the handful. Anthropic’s Project Rainier with Amazon runs on roughly half a million Trainium2 chips and anchors a commitment exceeding $100 billion over the decade and up to 5 gigawatts of capacity. Its expanded deal with Google and Broadcom adds 3.5 gigawatts of TPU compute from 2027. To buy the Google chips without diluting itself into oblivion, Anthropic turned to private credit: in early June, Apollo and Blackstone closed “Project Big Sky,” a $35 billion financing — one of the largest private credit deals ever — structured through a special purpose vehicle that pledges the chip leases themselves as collateral. The lenders insulated against the one risk no one can price: how fast does this hardware depreciate when geometry keeps improving?
Private credit at that scale needs to be serviced, and servicing it needs public liquidity. Which is why, at 9:36 AM Pacific on June 1, 2026, Anthropic filed a confidential draft S-1 with the SEC. Days earlier it had closed a $65 billion Series H at a $965 billion valuation. Hemmed in by Rule 135, which lets a company confirm a filing but bars it from saying anything else, Anthropic could only watch as the financial press conflated the $965 billion private mark with an IPO target and the $65 billion raise with IPO proceeds.
The Strange Loop
This is the detail that should keep the industry up at night. The misreporting was not primarily human error. Automated wires and LLM-driven aggregators metabolized the filing, confidently fused incompatible numbers, and in some cases stapled other companies’ valuations onto Anthropic. The company whose entire product is autonomous, long-horizon orchestration watched its most consequential corporate act distorted by exactly that — an agentic pipeline choosing speed over verification. The reporting layer and the reported company now run on the same underlying architecture. June 1 was a live demonstration of the hallucination failure mode Anthropic’s own alignment work exists to suppress, performed on Anthropic, by the genre of system Anthropic builds. The map drew itself, and got the territory wrong.
The Super-Cycle
This is the cycle this funds. Anthropic’s filing sits at the center of the most aggressive IPO super-cycle in modern memory, and its timing is hostage to a rocket. SpaceX lists on the Nasdaq on June 12 under SPCX, skipping the roadshow entirely and fixing its price at $135 a share to raise $75 billion at a $1.77 trillion valuation — a chunk of it earmarked for AI compute. If the market absorbs that without choking, Anthropic accelerates from confidential draft to public S-1; if SpaceX prints weak, the confidential process exists precisely so the filing can be quietly shelved. OpenAI, freshly restructured into a for-profit, trails toward a late-2026 listing near $852 billion, its own race to Wall Street inseparable from its race for silicon.
The trade is simple. Strip away the headlines and one sentence remains. The victor of this cycle will not be the lab with the most capital or the largest GPU array. It will be the one that most efficiently converts public money into geometrically optimized silicon — the one that maps the low-rank dimensions of cognition onto the physical layout of the chip with the least waste. The pile is over. The sculpture has begun, and the market has started pricing the chisel.
Filed from the field
— Bret Kerr
Context Jamming is a dispatch from ACRA Insight LLC on cross-model orchestration, AI safety, and the economics of the new cognitive stack.
GemClaw · Semantic Triple Transformation · LMaaS · Architectural Determinism
Subscribe at contextjamming.substack.com